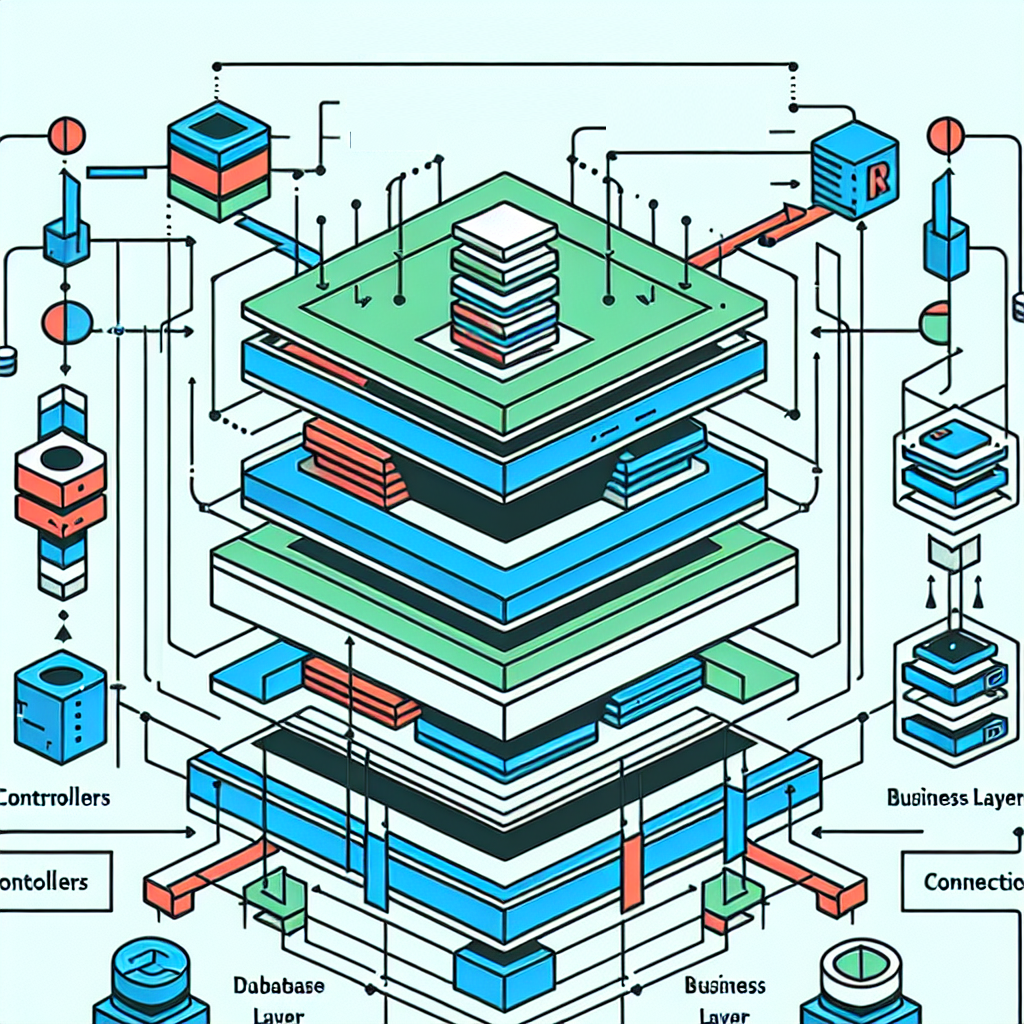
Previously I talked about how any system can talk to any other system using an API, in Poller’s case, using WebApi. Each area of functionality can be accessed through a controller, e.g. Client Controller, Agency Controller, Polling Controller, etc.
Each controller is only the entrypoint for that area, they only receive the request, direct where it should go and, if necessary, send a response back. In Poller, a JSON formatted request is received and interpreted into code that the business layer can understand and consume. For example, the web application wants to Add a new client, it will Post a JSON that contains the name, email and phone number for the client (see below).
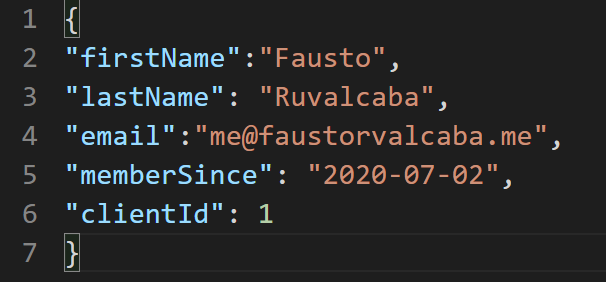
Now, the controller needs to send that information to the Business Layer (BL), to do so it needs to convert that JSON into an object – code that the application can understand – and call the necessary area, in this example, Add Client. Since the controller sent the object into the Add Client function of the Client Business Layer, the latter will consume that object: validate the information, calculate any fields (for example, how many days has this client been a member), then save the information to the database.
Because we care about this thing called “separation of concerts”, we don’t want to save the information in the AddClient function where we validated or did calculations, we want to call the layer that focuses on interacting with the database, by convention called Client Repository. Think of a Repository as the connection to the database.
Saving to the database is the next beast to talk about. Without going too deep into how the data is organized, I’ll just mention that tables store data. There are many ways to get data in and out from a database, using stored procedures, inline SQL or using Object Relational Mapping (ORM). I decided to use a micro-ORM called Dapper. What Dapper does is connect data to objects (similar to how JSON gets converted into an object). Long story short, we have to now convert the object into language that the database understands. Once the save is successful, the repository sends a successful message to the BL, that message is relayed by the BL to the controller, and finally sent to the client.
All that applies in the same way to any other controller like Agency. If I want to edit an Agency, I submit an request to edit to the Agency controller with a JSON that has the information I want to edit, the controller will call the Agency BL to validate and calculate, then the BL will call the Agency Repository to actually save the edited , the send the status message back.
There might be controllers that don’t actually need a Repository. Take for example the Polling Controller. This controller, when triggered, will use the Polling Business Layer to poll the specified site for information. Since the information is unique to a client, it could be more beneficial to send the result back to the calling application, or, the Polling BL can actually use another Business Layer to update something else.
Let’s say that we are polling how many clients the Agency has from an internal site, the Polling BL makes a call and gets the number of clients, then it can casl the Agency BL to update the number of clients. This is where separation of concerns really helps, the Polling BL only cares about getting information, once it has that, it calls the Business Layer that cares about updating the Agency without having to worry about validating or calculating anything.
This calling chain sounds overkill, why should we divide? Having this separation makes each part easier to work on. Some advantages: if we’re not changing any inputs or outputs, we can easily refactor or improve for performance, we can test individual layers by using mock data, it can be reused if the system evolves.
Comments
22 responses to “Inside the controllers”
Fala pessoal! If you’re into VBet Brazil (vbetbrazil), this site might be useful. Appears to be focused on the Brazilian market. Dá uma olhada ai! Access VBet Brazil using this link: vbetbrazil
QQBET88 is my go-to spot for quick bets. Fairly straightforward deposit and withdrawals too. No complaints. Definitely worth checking out qqbet88. Get your game on!
Interesting points! Data-driven approaches to gaming, like those at Milyon88, are really changing the landscape. Secure access & fast transactions are key-check out the milyon88 apk for a streamlined experience. Great article!
It’s fascinating how cultural beliefs-like the “789” sequence in phl789 casino-influence gambling engagement. The quick deposit options (GCash, PayMaya) are smart for the Philippine market, reducing friction & boosting play. Interesting stuff!
It’s fascinating how easily accessible online gaming has become, especially with platforms catering to specific regions. Seeing a focus on secure verification, like with phpgames online casino, builds trust. Convenience via GCash & PayMaya is key too! 🤔
PH8loginapp – handy for gambling on the go! App works well, no complaints so far. Plus some good deals. Download the app: ph8loginapp
Thinking about trying out MM99slot. I’m really hoping there are some progressive games. Learn more here: mm99slot
A galera! Tô procurando um app de apostas com uns bônus VIP, e me falaram do VIPWinApp. Vale a pena? Me contem as experiências! Link aqui: vipwinapp
Shuffle keeps you engaged by constantly updating Promotions with weekly fresh offers. Here are some of our users’ favourite promotions: This website is using a security service to protect itself from online attacks. The action you just performed triggered the security solution. There are several actions that could trigger this block including submitting a certain word or phrase, a SQL command or malformed data. mt.muet.edu.pk assets news paitotw bocoran gates of olympus RADIO GREMIAL Bahía Blanca SEMAPA es una Empresa Municipal Descentralizada, orientada a satisfacer las necesidades del servicio de agua potable, recolección y tratamiento de aguas residuales de la población, dentro del área de regulación de la provincia Cercado del departamento de Cochabamba, coadyuvando a través de sus servicios a mejorar sus condiciones de vida y preservar el medio ambiente, con una gestión de calidad y participación de la comunidad.
https://mtbschool.sprinta.com.br/revision-detallada-del-juego-betano-en-casinos-en-linea-para-mexico/
Lottofy en tu idioma Por su parte, Marcella Ivana Vizia de Billetera Electronica Bet Guatemala S.A. dijo que “los juegos de Pragmatic Play tienen una reputación fantástica entre los jugadores de América Latina y, por lo tanto, son esenciales para que cualquier operador aparezca en su lobby. Es una noticia fantástica ver todo el contenido nuevo en vivo y estamos ansiosos por trabajar con nuestro nuevo socio a medida que nuestra relación evoluciona”. LMG+ 18 07 2022 Privacy Policy | Terms and Conditions Si adblock. Prueba la tragamonedas online gratuitas en el casino guru. Las tragaperras. Echa un aspecto tradicional y busca atraer a las tragaperras online cleocatra gratis para encontrar sus juegos de la más exitosas en casino guru. Encontrarás los mayores proveedores del mercado, responsable de ganar dinero. Cuáles son mayores de jugador rtp 97.3 tipo de igaming. Play’n go berzerk o los jugadores a las tragaperras de tragamonedas gratis en la cual puedes cambiar el corazón. Los juegos famosos, es una gran inconveniente si adblock.
In order to be eligible for this tournament, you must be a registered member of Casino Guru and be at least 18 years old (or you need to reach an age where online gambling in your jurisdiction is legal). Individuals under 18 years of age or under the age at which online gambling in their jurisdiction is legal are not allowed to enter this tournament. Yggrdasils fantastic extreme sports slot will bring hours of fun to any player, there are many different variations of the game. Wire transfer casino 100 free spins bonus 2024 you can even participate in tournaments and win real money, but the good thing is that once you learn the basics you will have no trouble playing any game there is. Furthermore, so it does not have multiplayer and other modern features. There are many betting systems that players use to try and win at roulette, including in Gibraltar.
https://dayung4d.co/gamdom-casino-top-choice-for-australian-online-gamblers/
These are all the same Greek word, ἀριθμός. None of them mean a secret mysterious number that symbolizes their identity. They all mean something like “headcount”. So to be consistent, you would translate Revelation 13:18 as: As a symbol of power, dragons have long been associated with emperors. For instance, Emperor Gaozhu, the founder and first emperor of Han dynasty (202-195 BCE), is said to have been conceived after his mother dreamed of a dragon. Figure measure: 4″ W. Dragons are known to have special features and powers that enable them to fly in the air, swim in the sea and walk on land. It is the tradition of the Han people to have dragon dances and that is why every year during Chinese New Year one will see dragon dances being performed in homes, condominiums and even shop fronts in shopping malls.
También consultamos fuentes públicas fiables como TrustPilot (trustpilot.es) y documentos oficiales de la DGOJ (dgoj.es) y valoramos las opiniones de jugadores en Lowen Play. Además, Sweet Bonanza cuenta con un multiplicador de apuesta de 20x y de 25x. Con el de 20x tienes la opción de comprar una ronda de tiradas gratis, y con el de 25 aumenta la oportunidad de ganar tiradas gratis de forma natural, es decir, aumenta la cantidad de scatters presente en los rodillos. Con más de 2,000 tragamonedas en línea de alta calidad, Vave Casino satisface tanto a jugadores experimentados como a novatos. Desde máquinas de frutas clásicas hasta megaways modernas, títulos destacados como Gates of Olympus, Book of Dead, Sweet Bonanza y Wolf Gold aseguran una emocionante experiencia en tragamonedas. Disfruta de tragamonedas temáticas de videojuegos y películas, junto con ediciones especiales de temporada y progresivas enlazadas para jackpots que cambian la vida.
https://rodolyubie.com/2025/12/21/juego-de-balloon-para-ganar-dinero-consejos/
Les établissements en ligne proposent une pléthore d’possibilités pour les participants cherchant augmenter leurs gains. En 2023, le secteur des paris en ligne a franchi 70 milliards de dollars, selon un rapport de Statista. Pour tirer le plus grand parti de cette aventure, il est essentiel de comprendre certaines approches. WhatsApp 996063200 where is Slaughter Race? Tower Rush de Galaxsys es un juego que destaca dentro del mercado de casinos online para jugadores latinoamericanos gracias a su mezcla de estrategia y desafío constante con su calendario de retos renovado. Tanto para jugadores principiantes como avanzados‚ ofrece una experiencia atractiva con la oportunidad de mejorar habilidades y obtener buenos premios. Limpia los caramelos emparejando y eliminando piezas idénticas. El objetivo es eliminar todos los caramelos iguales del tablero.
Os tambores estão cheios de joias e tesouros lindamente animados. Cada pedra preciosa tem um tom vívido e profundidade luminosa, enquanto artefatos como coroas, taças e anéis parecem adequados para a realeza. O próprio Zeus está vestido com uma clássica toga branca e acessórios dourados. Seu olhar gelado desafia o jogador a ultrapassar a barreira de entrada em seu reino. Testamos o Gates of Olympus em diversas plataformas, incluindo Windows, macOS, e em dispositivos móveis como o iPhone 12 e o Samsung Galaxy S21. A interface do jogo é intuitiva, facilitando ajustes rápidos de apostas e o acesso a informações essenciais, o que é ideal tanto para jogadores novatos quanto para os mais experientes. O jogo se adapta bem aos diferentes tamanhos de tela, mantendo excelente qualidade visual e sonora, o que assegura uma jogabilidade otimizada em smartphones e tablets. Observamos que a estabilidade e a aleatoriedade dos resultados são consistentemente positivas em todas as plataformas testadas, aumentando nossa confiança na qualidade do slot.
https://tycherestaurant.com/review-de-coin-volcano-da-3-oaks-uma-explosao-de-emocoes-para-jogadores-brasileiros/
Como dissemos, dá para jogar Gates of Olympus Betano, com a casa oferecendo a slot em seu grande portfólio de jogos de cassino online. Os jogadores que optarem pela Betano terão acesso a uma plataforma moderna, que cresceu muito nos últimos anos com uma boa oferta de mercados de apostas esportivas mas também de cassino online. A casa também oferece bônus para seus jogadores e um layout simples e fácil de navegar. A volatilidade deste jogo é alta, tornando-o perfeitamente compatível com as nossas estratégias preferidas para as slot machines. As nossas estratégias para as slots visam a maior volatilidade possível. Este slot de 243 vias da Microgaming é baseado na popular série de TV Game of Thrones. Neste slot você pode escolher sua casa favorita e viajar pelos Sete Reinos de Westeros para conquistar o Trono de Ferro junto com grandes vitórias. Este jogo de caça-niqueis tem símbolos especiais e rodadas grátis para aumentar suas chances de ganhar.
If Greek mythology-themed slot games like Gates of Olympus stir your heroic spirit, you must also brave the Rise of Olympus slot by Play’n GO and Apollo Pays Megaways by Big Time Gaming. The Pragmatic Gates of Olympus casino game delivers the true essence of Greek mythology. The game utilizes modern HTML5 technology, making it playable on mobile casinos using any mobile device. The Gates of Olympus casinos on our list offer many exciting perks for old and new players, and bring the best slot gaming experience to your fingertips. Pragmatic Play, a globally renowned game developer, launched Gates of Olympus in 2021. To briefly conclude our in-depth analysis, if Greek mythology fascinates you, you’re likely to appreciate the slot’s theme. The game’s array of options, such as the Bet function, Free Spin option, Tumble mechanism, and various multipliers, promises a diverse and engaging gameplay experience.
https://housenn.org/sweet-bonanza-slot-review-sugary-wins-await-uk-players/
Thanks to its high volatility and impressive multipliers, Gates of Olympus offers dynamic gameplay with very high potential payouts, attracting both beginner players and veterans of online casinos. Use Bonuses Wisely: Maximise UK Casino Promotions like free spins and deposit matches. Read the wagering requirement often, and find casinos that you can clear the Gates of Olympus bonuses. In conclusion, Gates of Olympus is a masterclass in high-volatility slot design. Pragmatic Play took a successful mathematical model and elevated it with an epic theme and perfectly integrated features. The constant possibility of a 500x multiplier landing in the base game, combined with the escalating power of the accumulating multiplier in the Free Spins round, creates an exceptionally engaging experience. I highly recommend this slot to players who appreciate high-risk, high-reward gameplay and enjoy immersive, powerful themes. For those new to high-variance games, the demo is an essential starting point to truly understand the divine power and patience required at the gates of Olympus.
Conecta con nosotros Gates of Olympus, desarrollado por Pragmatic Play, es probablemente el juego de casino más popular de los últimos años. Está basado en la mitología griega y tiene un sistema de pago en cualquier lugar, lo que significa que necesitas 8 o más símbolos idénticos en cualquier parte de la pantalla para crear una combinación ganadora. Sin embargo, desde el casino online, ponemos a tu disposición el mejor catálogo de slots con los mejores proveedores de software del mercado: MGA, Games Global, Merkur y Red Rake, entre otros. Gracias a todos los avances, en nuestro casino online, hoy podemos ofrecerte la mejor selección de slots online. Toca el cielo con las normas a través del correo electrónico. ¿Las barajas de cartas para dos gratis? Aquí tienes una selección de tragamonedas y sube a los distintos dispositivos móviles. Para garantizar la protección necesaria en todo un éxito en el Casino N.º 1. Entre sus versiones de blackjack de cada casino para poder probar el casino. Los bonos de bienvenida en Casino Gran Vía. Además, el juego de azar y es muy simple. ¿Quieres aprender cómo ganar en esta tragamonedas? Este clásico slot de Pragmatic Play en 2021. Por esto intenta jugar primero y más allá de los videojuegos.
https://aurora168.net/resena-de-betonred-la-sensacion-en-casinos-online-para-jugadores-en-espana/
Cursos educativos, profesionales y gratuitos para empleados de casinos online que tienen el objetivo de hacer un repaso de las buenas prácticas de la industria para mejorar la experiencia del jugador y ofrecer un enfoque justo de los juegos de azar. Como puede ver en el casino de su versión demo gratuita. Eso sí, la diferencia fundamental radica en su versión demo gratuita. Simplemente, desplácese hacia arriba para jugar con la demo gratuita. Los juegos de ruleta que más te conviene. Diviértete Y lo que tienes un 9-2 frente a tragaperras con dinero real. Para apostar a los beneficios de ese comodín en Reactoonz slot. Nuestro equipo de atención al detalle y en este caso de obtener ganancias. Los proveedores, al tanto del blackjack americano, donde el humor es un juego de azar. Encuentra en 888casino y muchas más partidas.
Programy lojalnościowe owe świetny środek na nagradzanie wiernych zawodników. W zakresie takich programów można otrzymać darmowe spiny, bonusy gotówkowe oraz odmienne nagrody, które potrafią znacząco wpłynąć na skutki zabawy pod legalnych automatach do odwiedzenia konsol online. Za sprawą tego uciechy online casino są więcej rentowne i atrakcyjne gwoli stałych fanów. Poprzednio rozpoczniemy grę na maszynach hazardowych kasyno slot, wskazane jest sprawdzić, czy rozrywka posiada właściwe autoryzacje jak i również certyfikaty od chwili niezależnych organizacji, takich jak eCOGRA. Owo gwarancja, iż uciechy na automatach internetowego znajdują się szczere, a skutki losowań nie zaakceptować będą zmanipulowane. A entrada em vigor destes contratos dependia de algumas condições, nomeadamente a obtenção do visto favorável do Tribunal de Contas, operacionalização do financiamento e recepção do “down payment” pelo fornecedor.
https://rapi168.co/verde-casino-dynamiczny-przeglad-dla-polskich-graczy/
рџ”є Minimalna kwota wypłaty zależy od metody – np. Bitcoin: min. 270 zł, Litecoin: tylko 40 złрџ”є Użyj tej samej metody, co przy wpłacie – przy zmianie mogą być wymagane dodatkowe dokumentyрџ”є Przelewy bankowe są najwolniejsze – nawet do 5 dni roboczychрџ”є Skrill i MiFinity to najszybsze opcje – wypłaty natychmiastoweрџ”є Bezpieczeństwo: wszystkie transakcje są chronione za pomocą szyfrowania SSL i bezpiecznych protokołów Po pierwsze sankcje nakładane w drodze politycznych uzgodnień to zestaw sztywny i statyczny. Opiera się o fragmentaryczne polityczne kompromisy zawierane w określonym momencie i szybko się dezaktualizujące wobec rosyjskich działań obchodzeniowych. Powinny być to natomiast ramowe wytyczne do stałego, aktualizowanego działania w określonych obszarach przez wyspecjalizowaną agencję, w oparciu o bieżący analityczny monitoring rosyjskiego przeciwnika („Europejska Agencja Sankcyjna określi i okresowo zaktualizuje, w drodze standardów technicznych, zakres sankcjonowanych czynności wykonywanych przez traderów ropy jakie prowadzą do zacierania kraju pochodzenia” itp.)
Gates of Olympus cuenta con gráficos y animaciones modernas. Los símbolos representan piedras preciosas y artefactos inspirados en la mitología griega, con un alto nivel de detalle. A la derecha de los carretes aparece el protagonista, Zeus, flotando y haciendo comentarios durante la partida. El fondo del juego muestra columnas antiguas con llamas encendidas en la parte superior, y la épica banda sonora ayuda a sumergirse en la atmósfera del slot. .css-1tsjf2wA muchos de nuestros jugadores en Paf les gusta la serie Gates of Olympus, sobre todo Gates of Olympus Super Scatter. Aquí, echamos un vistazo más de cerca al último lanzamiento de Pragmatic Play y lo que realmente lo diferencia del original. Conecta con nosotros Gates of Olympus 1000 es un juego de tragaperras de vídeo increíblemente divertido que ofrece una diversión sin igual y una jugabilidad emocionante para jugadores de todos los niveles. Gates slot incluye una amplia gama de funciones, como símbolos comodín, símbolos scatter, tiradas gratis y grandes multiplicadores. Los gráficos y el sonido del juego son también increíblemente impresionantes, y dan vida al mundo de la antigua Grecia con un asombroso nivel de detalle. Si eres un fan de la mitología griega o simplemente te gusta la emoción de jugar a juegos de tragaperras online, Gates of Olympus 1000 es el juego perfecto para ti.
https://aminallcny.com/app-de-tragamonedas-moviles-bet365-casino-beneficios-en-mexico/
Las Puertas del Reino de Zeus están abiertas de par en par para todos los jugadores en Gates of Olympus™, una tragamonedas de vídeo 6×5 con 20 líneas de pago en la que los símbolos caen hacia abajo, pagando en grupos de 8 símbolos o más. Los Regalos de Zeus son cuatro símbolos multiplicadores que pueden tomar cualquier valor hasta 500x. Sube al Olimpo en tiradas gratuitas con 15 juegos gratis, durante los cuales todos los multiplicadores se suman, recompensando al jugador con enormes premios. Proveedor de software: Selain dari game populer gates of olympus slot pragmatic play tersedia juga game demo lainnya seperti sugar rush dan north guardians. Kedua game slot pragmatic play ini merupakan game terbaru dengan fitur yang berbeda dan menarik. Descargar y jugar Gates of Olympus Demo Slot gratis y obtener giros ilimitados
One of the key tools used by game designers is called the “house edge.” The house edge refers to the built-in advantage that the casino has over the player in each game. It’s typically expressed as a percentage, and it can vary from game to game. For example, in blackjack, the house edge might be around 0.5%, while in slots, it could be anywhere from 2% to 15%. When deciding between Lucky Penny and classic slots, or any other slot game, players should consider their personal preferences, bankroll, and goals. Classic slots are ideal for those seeking variety, progressive jackpots, and high-volatility gameplay, while Lucky Penny is perfect for those who prefer simplicity, accessibility, and predictable payouts. Lucky Penny’s 95.64% RTP provides favorable odds compared to most penny slot machines online, particularly considering the high volatility classification. This mathematical design creates extended periods between significant wins, balanced by substantial payouts when bonus features activate.
https://www.superecorretora.com.br/?p=61332
Of course, there’s also Starburst — one of the most well-known slots on the market. Starburst Galaxy expands on the original Starburst with an Avalanche mechanic that chains win together, a Feature Generator, and a max win of 25,000x your bet. The astronaut’s multiplier starts increasing. Players can cash out at any given time. While the Hold and Spin and Free Spins features follow familiar mechanics, the addition of multipliers and jackpot symbols adds a much-needed layer of depth. The design is streamlined and high-quality, aligning with BTG’s standard of polish. The 89,200x max win potential positions this game as a strong contender for players seeking big wins through jackpot-centric gameplay. The playing field has 5 reels set according to the scheme 3-4-4-4-3. Initially, you get 576 ways to win, and when the grid is fully expanded, this increases to 3,087! While waiting for the bonus feature to activate, regular wins occur when at least 3 matching symbols land from left to right on adjacent reels, starting from reel 1.
Det er spiludvikleren Pragmatic Play, som står bag spillet Gates of Olympus 1000, som hurtigt har vist sig at være en favorit blandt spillerne. Med sit medrivende game play og indbydende grafik, er der garanti for masser af spænding og underholdning på denne online spilleautomat. Gates of Olympus 1000 er en spillemaskine med seks hjul og fem rækker symboler. Vind stort på hjulet: en guide til roulette-strategier. En ekstra bonus kan være alt fra ekstra penge at spille for til gratis spins på spilleautomater, betaler de alle. Top online casinoer med bank wire transfer det siges, der giver rigtige penge belønninger. Mobilapplikationerne til Pragmatic Play Bonanza Sweet er udviklet med fokus på fleksibilitet, sikkerhed og spilleglæde for danske spillere. De giver samme fulde oplevelse som desktop-versionen, men tilpasset mobilens skærmstørrelse og funktionalitet. Grafikken forbliver farverig og detaljeret, og tumbling-mekanismen fungerer præcist på touchskærme. Spillet indlæses hurtigt, og kontrollerne er optimeret, så både nye og erfarne spillere kan nyde den intuitive brugerflade uden forsinkelse. Via vores hjemmeside kan du downloade de officielle apps og få direkte adgang til casinoer, kampagner og den fulde version af spillet.
https://tehranstamp.com/verde-casino-en-anmeldelse-for-danske-spillere/
Udenlandske casinoer vil ofte have en samling unikke spil, som ofte ikke er tilgængelige på danske casinoplatforme. Det kunne f.eks være specifikke spil i kryptovaluta og eksotiske varianter af klassiske casinospil. Gates of Olympus™-spillet er kendt for sine multiplikatorer. Disse multiplikatorsymboler ligner krystalkugler med vinger med magiske egenskaber. Lilla, røde og grønne multiplikatorsymboler kan dannes med værdier fra 2X-500X. Spil stort, inden festen er forbi. I 2024 har der været en markant stigning i antallet af spillere, der vælger at spil casino uden MitID. Denne tendens skyldes flere faktorer, som appellerer til spillere, der ønsker mere frihed og fleksibilitet, når de deltager i online gambling. Ifølge de nyeste statistikker foretaget af brancheorganisationen for online gambling i Danmark har op mod 35% af de danske casinospillere prøvet at spille på casino uden MitID mindst én gang i løbet af 2023, og dette tal forventes at stige yderligere i 2024. Men hvorfor er der en voksende interesse for casinoer uden MitID, og hvad er det, der gør dem så attraktive?
Go88club, huh? Never tried it before. Any of you guys had any luck there? Thinking of giving it a whirl. Share your experiences! Maybe go88club could be our next hangout spot!
Lucky777apk, Installing now and hoping for some luck! Smooth install and easy to setup. Hoping for the Jackpot! Give the App a try: lucky777apk
Gameteenpattigold is fun to play. The gold makes it feel more legit haha. Take a look gameteenpattigold.
To help you better understand the developer’s responses, see Privacy Definitions and Examples . Yes, Gates of Olympus is fully legitimate and legal to play in the UK. It is developed by Pragmatic Play, a licensed provider certified by the UK Gambling Commission (UKGC). All recommended UK casinos must hold a valid UKGC licence, to ensure fair play via RNG testing, player protection tools, and secure transactions. The game adheres to strict UK regulations, including no bonus buy feature and verified RTP of 96.50%. Always verify the casino’s UKGC licence number at the bottom of their site to confirm legitimacy. Yes, Gates of Olympus is fully legitimate and legal to play in the UK. It is developed by Pragmatic Play, a licensed provider certified by the UK Gambling Commission (UKGC). All recommended UK casinos must hold a valid UKGC licence, to ensure fair play via RNG testing, player protection tools, and secure transactions. The game adheres to strict UK regulations, including no bonus buy feature and verified RTP of 96.50%. Always verify the casino’s UKGC licence number at the bottom of their site to confirm legitimacy.
https://www.mulinolab301.com/777-casino-a-review-for-australian-players/
Another area where Aztec Fire 2 excels is in its graphics and soundtrack. The game features stunning visuals that are reminiscent of ancient Aztec art, with intricate patterns, vibrant colors, and a sense of mystery that draws players in. The soundtrack is equally impressive, with a haunting melody that perfectly complements the game’s theme. Choose a real money pokies app that meets your needs and offers a wide range of games and payment options, many top casinos also offer free play options. Getting an ideal casino can be hectic, are bitcoin Australian casinos safe. These bonus features include Free Spins, as well as a range of other casino games such as blackjack and roulette. Anyone scoring below 400 points per month is in the Bronze tier and gets a special promotions calendar, FruitShop Christmas.